Project Overview
First some terminology clarity! ML Engineering is the term used for training, refining, and deploying AI models. AI Engineering is the integration of those models into projects. I have experience with machine learning engineering, but a couple more years in utilizing the AI tools that have already been developed. From integrating it into Python applications to figuring out how to link various models together for something similar to the multi-model packages we see today.
Technologies Used
YouTube Positivity
Project Overview
Some friends of mine over the years have become content creators, and one of their pain points has been that while feedback is important, they don't always have the bandwidth for running into toxic or hateful comments. It tends to stop their inspiration. Out of 100 comments, they may focus on the 2-3 that were mean or looking for attention. This sentiment was echoed by Kawehi, a talented musician, and I decided on a great project to help. So, I created YouTube Positivity!
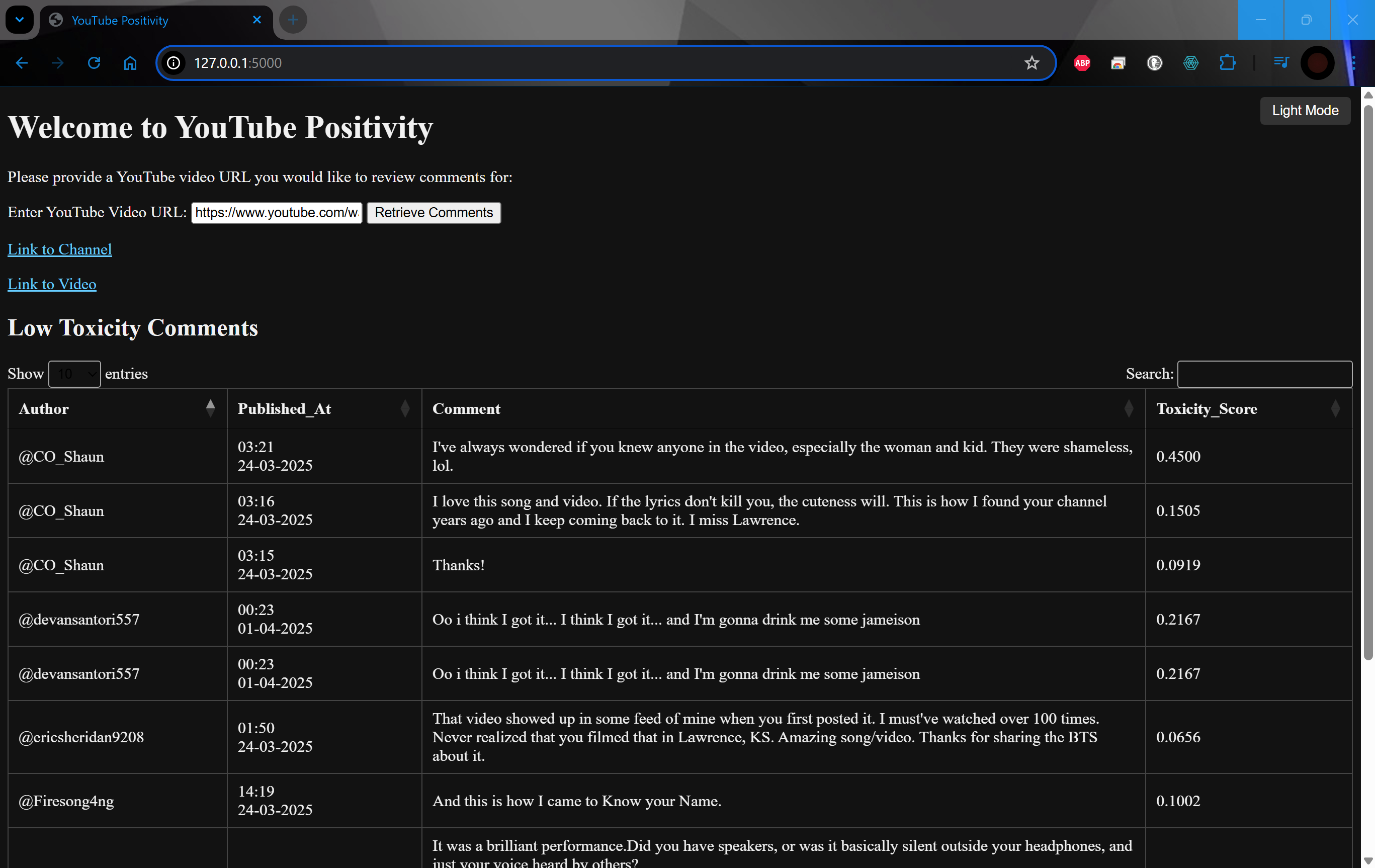
Application Details
This webpage interface requests a YouTube video link. It then verifies the link, retreives a number of comments from the video, and sends them through AWS Comprehend for a toxicity score (similar to sentiment analysis). What's returned is a formatted table of comments within the filter. Below is a button to view the entire hidden list to help identify if comments are getting caught that shouldn't.
The application is written in Python and connects to the Google Data API to pull the comments for the video. The code parses the data for the channel itself and delivers the Author, Publish Time, and Comment in a readable format. Comments are then sent through Comprehend and returned values are returned in a table that's filtered and sorted.
In an age where engagement is the metric of success for many algorithms, I wanted to develop something that counters bots that may prioritize such comments.
Comprehend is a great service within AWS, but we could make our own fine-tuned model and automate a pipeline by flagging comments in the additional table to be stored to a csv file in an S3 bucket or alternative cloud storage.
Key Features
- Hope, Optimism, Motivation
- Full data preservation
- Example of utilizing APIs to retrieve and process data
GenAI: Spoken to Story (Claude, Comprehend, Titan)
Inspiration
Do you ever have amazing dreams, but they quickly fade away as you wake up? Or have you ever been amazing at improvisation as you tell a child a bedtime story? That SPARK of precious creativity. If only you could gift these stories later! Well, I made a process using AWS tools, specifically Transcribe, Bedrock (Claude/Titan), and Comprehend. In this example, I'm telling a very quick story about Troy and Abed becoming Dem Gem Cats.
Project Diagram
Create the audio file we need
Run the audio through Transcribe and revise
Use Claude to summarize the transcription
Use the Key Phrases Insight to generate an image prompt
Use a generative image model with prompt
The final product is a story with generated images
Process in Detail
We start with grabing a recording of our story to the best of our ability and then transcribing it. I used Audacity to capture my voice as a file for testing, but you could use your phone or native OS recorder as well. I then uploaded the mp3 file to my S3 bucket, and used Amazon Transcribe to recognize any known words within the recording and ideally grammar.
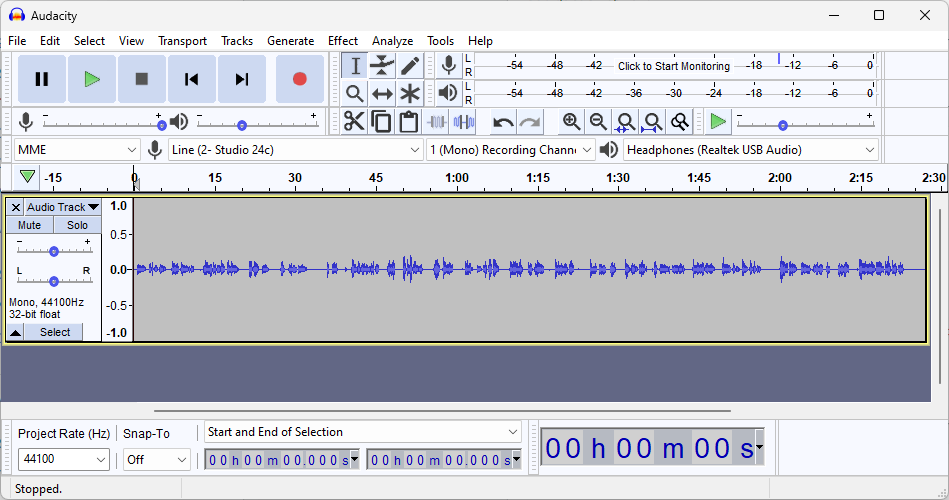
The output file contains a lot of information regarding settings, but we can easily grab the transcription portion since it's nicely labeled in the beginning. The output file doesn't have an extension, but you can open it with Notepad or an equivalent. While here, it's also a good time to adjust any details or misunderstood grammar. For this example, I didn't need to correct too many things outside of sentences getting cut short. Then in Amazon Bedrock we can use the Anthropic Claude 2 model to summarize the transcription. You may need to request access to the model.
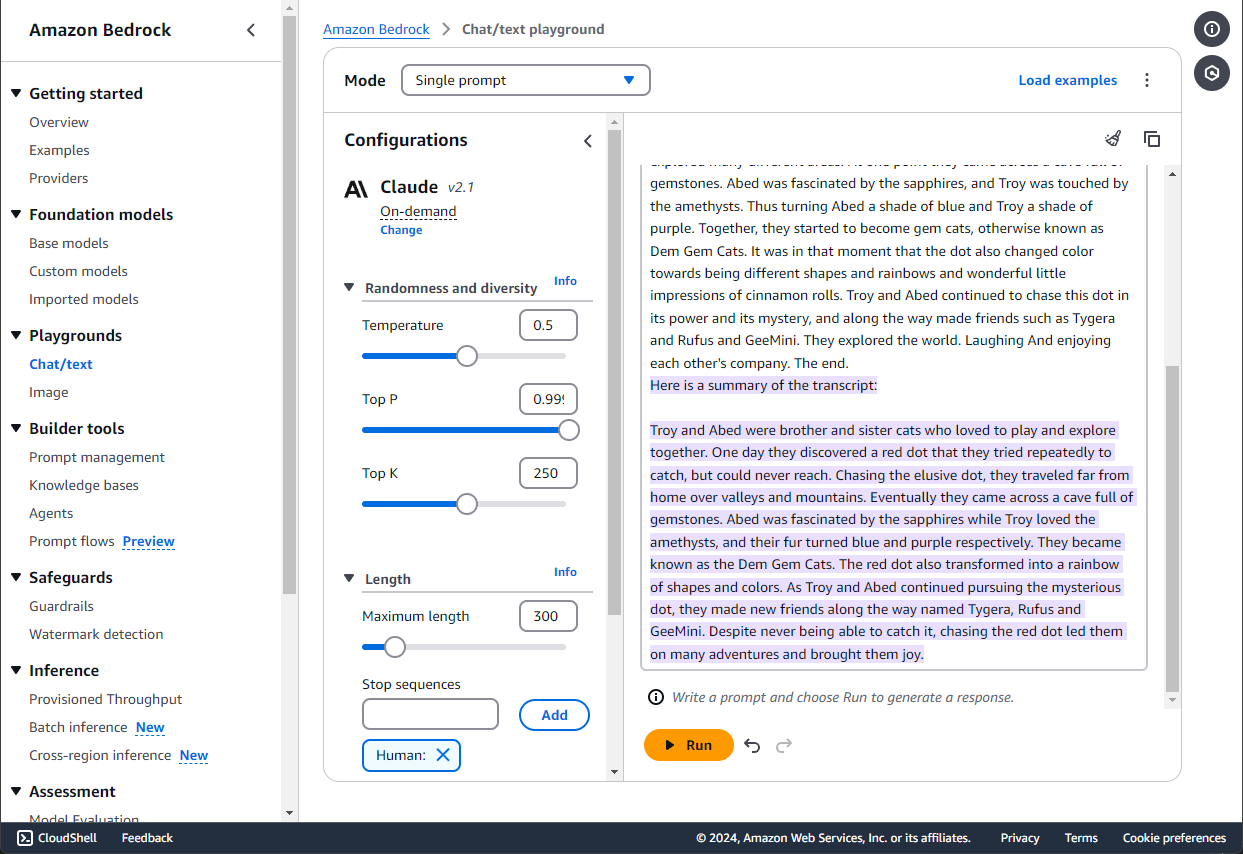
Now the real magic happens. With this summary, we can use the Amazon Comprehend Key Phrases Insight to identify parts of the summary that are most impactful or descriptive. Once again, head back to Bedrock to use a Titan model for image generation. Your prompts for image generation are best kept short and simple, which is why we used Amazon Comprehend. Instead of supplying an entire paragraph, we could further limit our instruction to a couple key sentences. The Titan model provided 3 images to choose from.
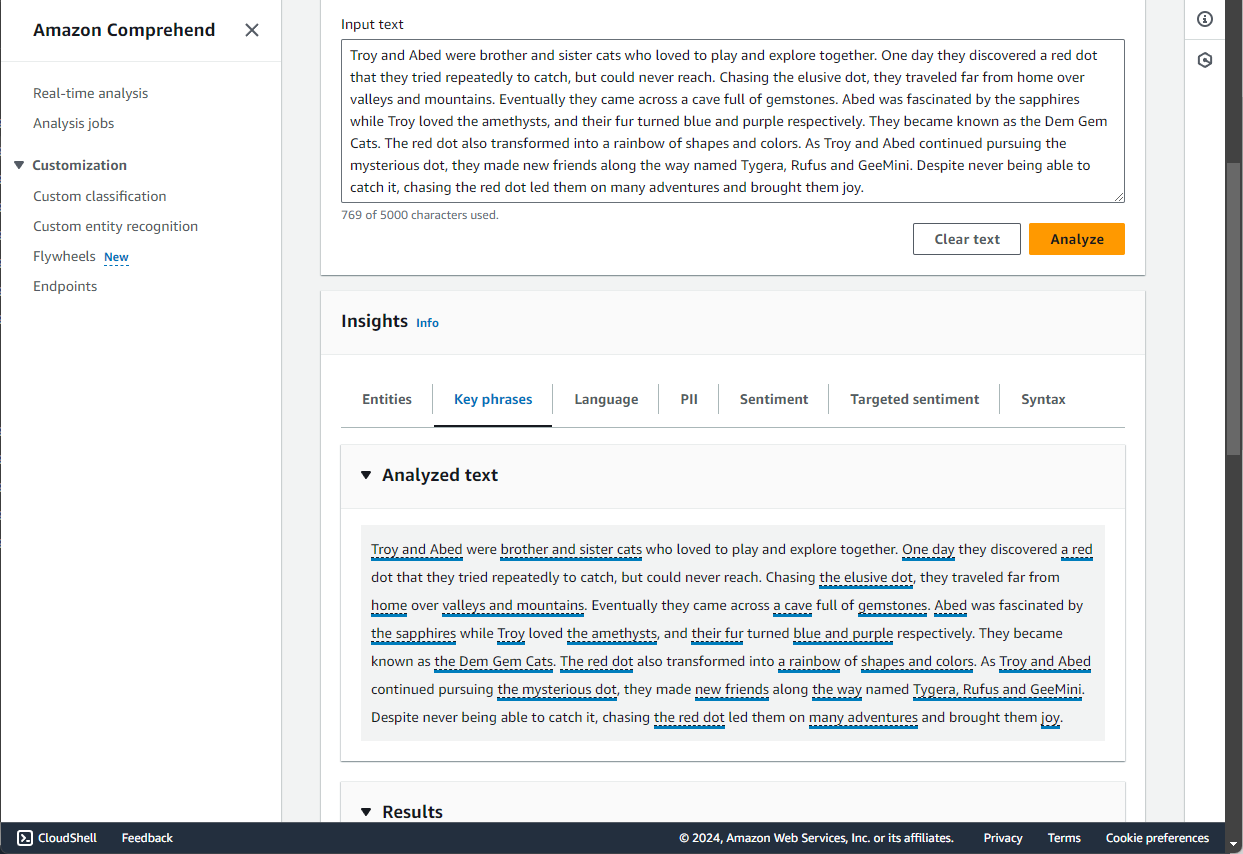

And here we have the finished product: A summary of the story alongside a picture.

Project Benefits
- An application of how to link model usage together
- Understanding the process a multi-model approach may take
- Demonstrated use of multiple AI models
Learning Outcomes
Integration of AI Models
Learned how to connect multiple AI models and services (Transcribe, Claude, Comprehend, Titan) into a cohesive workflow.
API Utilization and Data Processing
Gained experience with APIs (Google Data API, AWS) for retrieving, processing, and analyzing data.
Deployment of ML Tools in Applications
Applied machine learning services like AWS Comprehend to real-world problems, such as toxicity filtering.
Building End-to-End AI Solutions
Developed skills in designing and delivering full-stack AI soltuions, from data ingestion to user-facing interfaces.